#execute hive query
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
Chapters: 5/?
Rating: Explicit
Relationships: The Emperor/Tav
Summary:
She wanted the power more than anything, but more than that she wanted to share it with the one who was most deserving of her gratitude, her affection. Never one to deny herself, the adventurer saw no reason why her personal ambitions could not manifest alongside the desires of her heart.
"We can rule the world. Together."
It was a grave and terrible calculation.
——
Why did she submit?
The question intruded on his thoughts, and not for the first time. It was a tantalizing, unbalanced equation, tempting him with the promise of insight. Falexima was a proud creature, more so than most humans. She was about as likely to willingly submit to his control as Lae’zel of Crèche Kilir… but that was a determination he had made in error, the Emperor realized, a conclusion borne from too-little data and far too much confidence in her habit of succumbing to baser physical impulse. To know the answer was to know Falexima’s true motives, and the Emperor could not allow that opportunity to wither.
He paused his preparations, setting the rune slate he had been absorbing data from aside. He stacked it with the other slates, to be absorbed at a later time for a more comprehensive analysis of the githyanki’s next move. The Emperor steepled his long fingers, at last giving the disruptive query his full and undivided attention.
Choosing to release Falexima at the Elfsong Tavern had presented considerable risk to his nascent operations. The Emperor, therefore, had expected that she would lash out at him in resentment for enthralling her. Knowing her to be an opportunistic creature, he prepared seventy-nine possible contingencies, to be executed in the event of Falexima taking full advantage of her temporary freedom. But even with the Netherbrain helping to facilitate those calculations, the Emperor had not been able to anticipate her surprising decision not��to rebel.
For as much time as he spent watching her, reading her thoughts, there was still far too much he did not know about her, about from where and whence she acquired her radical thought processes, the ideas that seemed random and chaotic at first glance but gradually revealed themselves to be part of a more profound and long-pursued ambition.
Would her mind never cease to fascinate him? Blooms of pleasant regard spread through the Emperor’s neural pathways, flooding him with bonding chemicals typically reserved for hive function, now gloriously wasted. She was an endless source of enjoyment, an indulgence, a drug.
She could never know the true extent of her influence over him, the Emperor decided. And she never would, so long as he kept her enthralled. But that notion was also profoundly unsatisfying, even demoralizing. A Grand Exchange without her input, without her unbridled ideas, caused bundles of neurons within his hippocampus to physically sting him. It was the impact of memory — of Ansur, he realized, who he let go of.
Emotion did not come easily to the Emperor anymore. For much of his illithid existence he had been convinced he was incapable of it. But that was an inaccurate assessment also. Ansur’s betrayal was so distant to him it seemed almost clinical in its initial choice. The Emperor understood the dragon’s reasoning for what it was, and had reacted in kind, preserving himself. But what remained always was the void of Ansur’s absence, the longing to share with him all he had discovered and achieved in their time apart. That void grew upon learning of Belynne’s murder. It would grow again without Falexima also.
But this line of thinking was ancillary, and not conducive to his current objective. Refocusing, the Emperor levitated upright out of the chair and floated away from the workstation.
The undercity tunnels were busy with activity. Thralls applied stone and mortar with basic masonry tools while illithids reinforced them with the bioorganic tissue and exoskeleton-like material produced by the elder brain — a by-product of its feeding within the morphic pool. It was a necessary construction, though admittedly a hurried one. The subterranean layers of the city were an infrastructure disaster waiting to happen, and the Absolute’s invasion had only exacerbated the problem. It was certainly apparent within the Temple of Bhaal, which had been carved out of the earth by the dead god’s insane fanatics with little regard for the buildings and street above it. So much verticality beneath Baldur’s Gate could only result in the city eventually collapsing in on itself, especially with the recent damage it sustained.
It was to the former temple that the Emperor proceeded. Orin the Red’s mess of viscera and gore had been for the most part cleaned. Too few of the corpses that she had kept on display held brains fresh enough to feed the colony, so the Emperor had them hauled up to the surface and turned over to the Flaming Fist, who were then given instructions to identify what bodies they could and give the citizens the opportunity to claim any kin that had been reported missing. An official statement was distributed also, which described the extent of the Cult of Bhaal’s crimes and “the Absolute’s” role in ending them. Doing so earned the colony a minor amount of good will, but more importantly, it demonstrated to the populace that illithid kind were establishing a sense of order and safety that the city had arguably always lacked.
He floated downwards and landed in the middle of Bhaal’s inner sanctum. The massive, skull-shaped relief still adorned the stone wall across the chasm, though it was gradually being obscured by the pulsing tissue which had begun to web across the structure. The Emperor slowly turned to get a good look at the circular chamber with his own eyes. Through Falexima’s he had witnessed how easily Orin became unraveled by the sorceress’s taunts. The Emperor recalled both the hatred and satisfaction Falexima experienced in that moment when the would-be Bhaalspawn was slain. She had never felt particularly threatened by the shapeshifter, but the pale-eyed woman irritated her immensely, to the point where Falexima’s bursts of frustration reached the Emperor as harmless spikes of psionic energy that managed to reach him even in the Astral Sea.
The sacrificial altar to Bhaal had been destroyed and removed, and a neural console engineered in it’s place. The surrounding alcoves that once served as displays for Orin’s corpses would soon accommodate ceremorphosis pods to nurse newly created mind flayers, though not immediately. The Emperor had other pressing priorities, and increasing their ranks was not among them. But the pods would at least be in place so that numbers could be replenished in the event of significant aggression from Vlaakith.
Visiting the chamber and reflecting upon Falexima’s experience there did not provide him any new insight, so the Emperor made the short journey to the morphic pool, where he had left the Netherbrain once again after dominating it. The branching tunnels there were also significantly changed, some collapsed outright as a direct result of the Netherbrain rising from beneath the Upper City to begin its assault. The Chionthar, having begun to flood the ancient sewers, had to be dammed quickly in order to prevent further ruin of the city. It had been amongst the first of the Emperor’s priorities. For days the mind flayers held the waters back with combined telekinetic force while conscripted and enthralled workers built the dams and emergency levees that would enable repairs. He found a few of those mind flayers there still, redirecting water flows and streams that were leaking into the surviving tunnels.
A new dock had also been constructed, as well as a makeshift-island made partially of the chitinous by-product of the Netherbrain as well as the rubble of the destroyed buildings taken from above. The Emperor flew carefully across the water and brine, hyper-aware of the Netherbrain’s physical presence nearby. The gargantuan illthid was partially submerged, bathing and healing in the brine whilst chafing against his hold. The Emperor sensed a slight tremor of resistance on it’s part and he responded by focusing on the Netherstones. The tips of the Crown of Karsus glowed faintly above the water and he felt the Netherbrain once again submit, becoming compliant.
A swirling, magical mist manifested before the Emperor as he landed carefully upon the island. Gale Dekarios emerged from it, greeting him with a smiling expression that the Emperor took to mean as friendly in regard. His beard was better kept than when the Emperor had last seen him, but he had a sleepless look under his eyes. The Emperor sensed a certain level of weariness being exerted from the wizard’s motor cortex.
“Ah. I was wondering when you were going to check in on us again,” said Gale. “She’s a stubborn one, this brain, but I’ve learned that she quite enjoys being scratched between the wrinkles. Who could have guessed that one might never have enough mage hands?”
Completed Chapter on AO3
#first ever chapter in the Emperor’s POV#That being said this is also the longest chapter I’ve ever written at nearly 12k words#blackmagecat writes#baldur's gate 3#bg3#the emperor#tav
2 notes
·
View notes
Text
What is Amazon EMR architecture? And Service Layers

Describe Amazon EMR architecture
The storage layer includes your cluster's numerous file systems. Examples of various storage options.
The Hadoop Distributed File System (HDFS) is scalable and distributed. HDFS keeps several copies of its data on cluster instances to prevent data loss if one instance dies. Shutting down a cluster recovers HDFS, or ephemeral storage. HDFS's capacity to cache interim findings benefits MapReduce and random input/output workloads.
Amazon EMR improves Hadoop with the EMR File System (EMRFS) to enable direct access to Amazon S3 data like HDFS. The file system in your cluster may be HDFS or Amazon S3. Most input and output data are stored on Amazon S3, while intermediate results are stored on HDFS.
A disc that is locally attached is called the local file system. Every Hadoop cluster Amazon EC2 instance includes an instance store, a specified block of disc storage. Amazon EC2 instances only store storage volume data during their lifespan.
Data processing jobs are scheduled and cluster resources are handled via the resource management layer. Amazon EMR defaults to centrally managing cluster resources for multiple data-processing frameworks using Apache Hadoop 2.0's YARN component. Not all Amazon EMR frameworks and apps use YARN for resource management. Amazon EMR has an agent on every node that connects, monitors cluster health, and manages YARN items.
Amazon EMR's built-in YARN job scheduling logic ensures that running tasks don't fail when Spot Instances' task nodes fail due to their frequent use. Amazon EMR limits application master process execution to core nodes. Controlling active jobs requires a continuous application master process.
YARN node labels are incorporated into Amazon EMR 5.19.0 and later. Previous editions used code patches. YARN capacity-scheduler and fair-scheduler use node labels by default, with yarn-site and capacity-scheduler configuration classes. Amazon EMR automatically labels core nodes and schedules application masters on them. This feature can be disabled or changed by manually altering yarn-site and capacity-scheduler configuration class settings or related XML files.
Data processing frameworks power data analysis and processing. Many frameworks use YARN or their own resource management systems. Streaming, in-memory, batch, interactive, and other processing frameworks exist. Use case determines framework. Application layer languages and interfaces that communicate with processed data are affected. Amazon EMR uses Spark and Hadoop MapReduce mostly.
Distributed computing employs open-source Hadoop MapReduce. You provide Map and Reduce functions, and it handles all the logic, making parallel distributed applications easier. Map converts data to intermediate results, which are key-value pairs. The Reduce function combines intermediate results and runs additional algorithms to produce the final output. Hive is one of numerous MapReduce frameworks that can automate Map and Reduce operations.
Apache Spark: Spark is a cluster infrastructure and programming language for big data. Spark stores datasets in memory and executes using directed acyclic networks instead of Hadoop MapReduce. EMRFS helps Spark on Amazon EMR users access S3 data. Interactive query and SparkSQL modules are supported.
Amazon EMR supports Hive, Pig, and Spark Streaming. The programs can build data warehouses, employ machine learning, create stream processing applications, and create processing workloads in higher-level languages. Amazon EMR allows open-source apps with their own cluster management instead of YARN.
Amazon EMR supports many libraries and languages for app connections. Streaming, Spark SQL, MLlib, and GraphX work with Spark, while MapReduce uses Java, Hive, or Pig.
#AmazonEMRarchitecture#EMRFileSystem#HadoopDistributedFileSystem#Localfilesystem#Clusterresource#HadoopMapReduce#Technology#technews#technologynews#NEWS#govindhtech
0 notes
Text
Understanding Execution Plans in HiveQL Language
HiveQL Query Execution Plans: A Complete Guide to Optimizing Hive Queries Hello, data enthusiasts! In this blog post, we’ll dive into HiveQL Query Execution Plans – one of the most powerful and insightful features of the HiveQL language: query execution plans. Execution plans show how Hive interprets and runs your SQL-like queries behind the scenes. They help you understand the performance of…
0 notes
Text
Navigating Unity Catalog Migration: Key Strategies for Seamless UC Migration
The world of data management is constantly evolving, and keeping your infrastructure up-to-date is crucial for optimal performance and security. Unity Catalog, Databricks' innovative metastore, offers a centralized platform for managing data and AI assets across various cloud environments. If you're considering migrating from a traditional metastore like Hive or Glue to Unity Catalog, this guide will equip you with key strategies to ensure a seamless UC migration.
Why Migrate to Unity Catalog?
There are several compelling reasons to leverage Unity Catalog for your data management needs. Here are a few key benefits:
Centralized Control: Unlike regional metastores, Unity Catalog provides a single source of truth for data lineage, access control, and governance. This simplifies management and ensures consistency across your data landscape.
Seamless Cloud Integration: Unity Catalog functions seamlessly across various cloud providers, eliminating the need for separate metastores for each environment. This fosters data portability and flexibility.
Enhanced Data Governance: UC migration empowers you with robust data governance features. Manage user permissions, track data lineage, and implement fine-grained access controls for improved data security and compliance.
Key Strategies for a Smooth Unity Catalog Migration
Planning and preparation are paramount for a successful UC migration. Here are some critical strategies to consider:
Thorough Inventory and Assessment: Before initiating the migration, take stock of your existing data assets in the source metastore. Analyze table structures, data lineage, and access control configurations. This comprehensive understanding will guide the migration process and minimize disruptions.
Develop a Migration Plan: Create a detailed migration plan outlining the sequence of steps involved. This includes defining migration batches, scheduling downtime windows, and assigning ownership for specific tasks. A well-defined plan ensures a smooth and efficient transition.
Leverage Unity Catalog Tools: Databricks offers a set of migration tools to simplify the UC migration process. These tools can automate schema conversion, data transfer, and permission mapping, reducing manual effort and potential errors.
Testing and Validation: Rigorous testing is crucial before transitioning fully to Unity Catalog. Utilize a test environment to validate data integrity, functionality, and user access after migration. This proactive approach minimizes risks and ensures a smooth transition.
Ongoing Monitoring: Once the migration is complete, monitor your Unity Catalog performance closely. Track key metrics like data access, query latency, and catalog health. Proactive monitoring helps identify and address any potential issues early on.
A Smooth Unity Catalog Migration with Celebal Technologies
Migrating to Unity Catalog can unlock significant advantages for your data management strategy. However, the process requires careful planning and execution. Celebal Technologies, a leading data engineering expert, can be your trusted partner in your UC migration journey.
Our team of experienced data engineers possesses in-depth knowledge of Unity Catalog and the broader data management landscape. We can guide you through every step of the migration process, from initial assessment to post-migration monitoring. With Celebal Technologies by your side, you can ensure a seamless and successful UC migration, paving the way for a more efficient and secure data-driven future. Contact Celebal Technologies today to discuss your Unity Catalog migration needs!
0 notes
Text
Modern Data Scientist: Technical and Soft Skills You Need to be successful

What skills are required to be a Data Scientist? OR Is strong mathematics background required to pursue a career as a data scientist? We at Rang Technologies see a lot of questions like this. It's hard when you're trying to break into the field to know exactly how much math & stats you need. Primarily, it depends on how a company is defining "data scientist." Some companies say "data scientist" but really mean "data engineer", which is much more focused on the software engineering side of things and strong with coding production systems, data storage and extraction, cluster management etc. The latter is less Math/Stats and more CS focused. Secondly it depends on how a company is dividing responsibilities. Some look for people who are either strong in programming or strong in mathematics/statistics, and then combine them in a team. Others look for "fully fledged" data scientists who have the deep insight in different models and when to apply which algorithms and can do all the implementation of the data. How the role you're looking at fits into these descriptions will affect how much math/stats you need to demonstrate. Given the variance, the trick is to carefully dissect the job posting and dig into the background of the current team. LinkedIn is a great place to do this. You can generally figure out the different roles (job titles) as well as see the skills/background people in these roles have. That said, there are a few mainstays that, irrespective of role, you should be demonstrating on your resume. Either through your academic courses/coursework, online courses you've taken, or project work you've completed (including write-ups that demonstrate your understanding). Specifically:
Linear algebra (and ideally basic multivariate calculus)
Regression ... linear regression and the things that violate the assumptions of linear models (e.g., autocorrelation in time series data, non-independent observations)
Probability theory ... especially Bayes' Law and Central Limit Theorem
Numerical analysis (e.g., time series analysis and forecasting)
Core machine learning methods (clustering, decision trees, k-NN)
How to take action now?
Compare this list of mainstays versus your resume. Which do you cover off? Which are you missing? Of those, which have you used or are proficient with? Time to make space to mention them - and if it is via project work, think about linking to a more detailed write-up (for example on GitHub) so you can highlight a deeper level of understanding. This is especially important for non-Math/Stats candidates, as the burden of proof is higher! If you've covered more than the above, great! Make sure the most relevant courses shine through and get you noticed. Technical Skills: Analytics Education - Data scientists are highly educated - 88% have at least a Master's degree and 46% have PhDs - and while there are notable exceptions, a very strong educational background is usually required to develop the depth of knowledge necessary to be a data scientist. Their most common fields of study are Mathematics and Statistics (32%), followed by Computer Science (19%) and Engineering (16%). SAS and/or R - In-depth knowledge of at least one of these analytical tools, for data science R is generally preferred. Skills Required are as below: Technical Skills: Computer Science Python Coding: Python is the most common coding language I typically see required in data science roles, along with Java, Perl, or C/C++. Hadoop Platform: Although this isn't always a requirement, it is heavily preferred in many cases. Having experience with Hive or Pig is also a strong selling point. Familiarity with cloud tools such as Amazon S3 can also be beneficial. SQL Database/Coding: Even though NoSQL and Hadoop have become a large component of data science, it is still expected that a candidate will be able to write and execute complex queries in SQL. Unstructured data: It is critical that a data scientist be able to work with unstructured data, whether it is from social media, video feeds or audio. About Rang Technologies: Headquartered in New Jersey, Rang Technologies has dedicated over a decade delivering innovative solutions and best talent to help businesses get the most out of the latest technologies in their digital transformation journey. Read More...
0 notes
Text
"Apache Spark: The Leading Big Data Platform with Fast, Flexible, Developer-Friendly Features Used by Major Tech Giants and Government Agencies Worldwide."
What is Apache Spark? The Big Data Platform that Crushed Hadoop

Apache Spark is a powerful data processing framework designed for large-scale SQL, batch processing, stream processing, and machine learning tasks. With its fast, flexible, and developer-friendly nature, Spark has become the leading platform in the world of big data. In this article, we will explore the key features and real-world applications of Apache Spark, as well as its significance in the digital age.
Apache Spark defined
Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets. It can distribute data processing tasks across multiple computers, either on its own or in conjunction with other distributed computing tools. This capability is crucial in the realm of big data and machine learning, where massive computing power is necessary to analyze and process vast amounts of data. Spark eases the programming burden of these tasks by offering an easy-to-use API that abstracts away much of the complexities of distributed computing and big data processing.
What is Spark in big data
In the context of big data, the term "big data" refers to the rapid growth of various types of data - structured data in database tables, unstructured data in business documents and emails, semi-structured data in system log files and web pages, and more. Unlike traditional analytics, which focused solely on structured data within data warehouses, modern analytics encompasses insights derived from diverse data sources and revolves around the concept of a data lake. Apache Spark was specifically designed to address the challenges posed by this new paradigm.
Originally developed at U.C. Berkeley in 2009, Apache Spark has become a prominent distributed processing framework for big data. Flexibility lies at the core of Spark's appeal, as it can be deployed in various ways and supports multiple programming languages such as Java, Scala, Python, and R. Furthermore, Spark provides extensive support for SQL, streaming data, machine learning, and graph processing. Its widespread adoption by major companies and organizations, including Apple, IBM, and Microsoft, highlights its significance in the big data landscape.
Spark RDD
Resilient Distributed Dataset (RDD) forms the foundation of Apache Spark. An RDD is an immutable collection of objects that can be split across a computing cluster. Spark performs operations on RDDs in a parallel batch process, enabling fast and scalable parallel processing. The RDD concept allows Spark to transform user's data processing commands into a Directed Acyclic Graph (DAG), which serves as the scheduling layer determining the tasks, nodes, and sequence of execution.
Apache Spark can create RDDs from various data sources, including text files, SQL databases, NoSQL stores like Cassandra and MongoDB, Amazon S3 buckets, and more. Moreover, Spark's core API provides built-in support for joining data sets, filtering, sampling, and aggregation, offering developers powerful data manipulation capabilities.
Spark SQL
Spark SQL has emerged as a vital component of the Apache Spark project, providing a high-level API for processing structured data. Spark SQL adopts a dataframe approach inspired by R and Python's Pandas library, making it accessible to both developers and analysts. Alongside standard SQL support, Spark SQL offers a wide range of data access methods, including JSON, HDFS, Apache Hive, JDBC, Apache ORC, and Apache Parquet. Additional data stores, such as Apache Cassandra and MongoDB, can be integrated using separate connectors from the Spark Packages ecosystem.
Spark SQL utilizes Catalyst, Spark's query optimizer, to optimize data locality and computation. Since Spark 2.x, Spark SQL's dataframe and dataset interfaces have become the recommended approach for development, promoting a more efficient and type-safe method for data processing. While the RDD interface remains available, it is typically used when lower-level control or specialized performance optimizations are required.
Spark MLlib and MLflow
Apache Spark includes libraries for machine learning and graph analysis at scale. MLlib offers a framework for building machine learning pipelines, facilitating the implementation of feature extraction, selection, and transformations on structured datasets. The library also features distributed implementations of clustering and classification algorithms, such as k-means clustering and random forests.
MLflow, although not an official part of Apache Spark, is an open-source platform for managing the machine learning lifecycle. The integration of MLflow with Apache Spark enables features such as experiment tracking, model registries, packaging, and user-defined functions (UDFs) for easy inference at scale.
Structured Streaming
Structured Streaming provides a high-level API for creating infinite streaming dataframes and datasets within Apache Spark. It supersedes the legacy Spark Streaming component, addressing pain points encountered by developers in event-time aggregations and late message delivery. With Structured Streaming, all queries go through Spark's Catalyst query optimizer and can be run interactively, allowing users to perform SQL queries against live streaming data. The API also supports watermarking, windowing techniques, and the ability to treat streams as tables and vice versa.
Delta Lake
Delta Lake is a separate project from Apache Spark but has become essential in the Spark ecosystem. Delta Lake augments data lakes with features such as ACID transactions, unified querying semantics for batch and stream processing, schema enforcement, full data audit history, and scalability for exabytes of data. Its adoption has contributed to the rise of the Lakehouse Architecture, eliminating the need for a separate data warehouse for business intelligence purposes.
Pandas API on Spark
The Pandas library is widely used for data manipulation and analysis in Python. Apache Spark 3.2 introduced a new API that allows a significant portion of the Pandas API to be used transparently with Spark. This compatibility enables data scientists to leverage Spark's distributed execution capabilities while benefiting from the familiar Pandas interface. Approximately 80% of the Pandas API is currently covered, with ongoing efforts to increase coverage in future releases.
Running Apache Spark
An Apache Spark application consists of two main components: a driver and executors. The driver converts the user's code into tasks that can be distributed across worker nodes, while the executors run these tasks on the worker nodes. A cluster manager mediates communication between the driver and executors. Apache Spark can run in a stand-alone cluster mode, but is more commonly used with resource or cluster management systems such as Hadoop YARN or Kubernetes. Managed solutions for Apache Spark are also available on major cloud providers, including Amazon EMR, Azure HDInsight, and Google Cloud Dataproc.
Databricks Lakehouse Platform
Databricks, the company behind Apache Spark, offers a managed cloud service that provides Apache Spark clusters, streaming support, integrated notebook development, and optimized I/O performance. The Databricks Lakehouse Platform, available on multiple cloud providers, has become the de facto way many users interact with Apache Spark.
Apache Spark Tutorials
If you're interested in learning Apache Spark, we recommend starting with the Databricks learning portal, which offers a comprehensive introduction to Apache Spark (with a slight bias towards the Databricks Platform). For a more in-depth exploration of Apache Spark's features, the Spark Workshop is a great resource. Additionally, books such as "Spark: The Definitive Guide" and "High-Performance Spark" provide detailed insights into Apache Spark's capabilities and best practices for data processing at scale.
Conclusion
Apache Spark has revolutionized the way large-scale data processing and analytics are performed. With its fast and developer-friendly nature, Spark has surpassed its predecessor, Hadoop, and become the leading big data platform. Its extensive features, including Spark SQL, MLlib, Structured Streaming, and Delta Lake, make it a powerful tool for processing complex data sets and building machine learning models. Whether deployed in a stand-alone cluster or as part of a managed cloud service like Databricks, Apache Spark offers unparalleled scalability and performance. As companies increasingly rely on big data for decision-making, mastering Apache Spark is essential for businesses seeking to leverage their data assets effectively.
Sponsored by RoamNook
This article was brought to you by RoamNook, an innovative technology company specializing in IT consultation, custom software development, and digital marketing. RoamNook's main goal is to fuel digital growth by providing cutting-edge solutions for businesses. Whether you need assistance with data processing, machine learning, or building scalable applications, RoamNook has the expertise to drive your digital transformation. Visit https://www.roamnook.com to learn more about how RoamNook can help your organization thrive in the digital age.
0 notes
Text
UAE Bike Sharing Market: Forthcoming Trends and Share Analysis by 2030
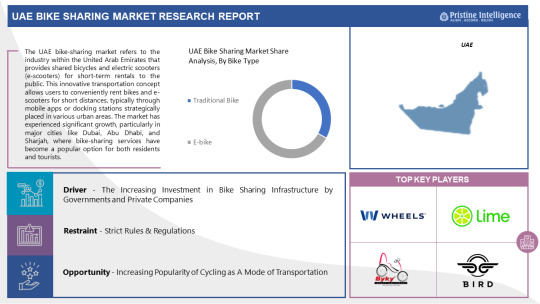
The UAE Bike Sharing is Expected to Grow at a Significant Growth Rate, and the Forecast Period is 2023-2030, Considering the Base Year as 2022.
The industry in the United Arab Emirates that offers shared bicycles and electric scooters (also known as e-scooters) for short-term public rentals is known as the "UAE bike-sharing market." Through mobile apps or docking stations positioned thoughtfully around different urban locations, customers may rent bikes and e-scooters for short distances with ease thanks to this creative transportation idea. Bike-sharing programs have been a popular choice for both residents and tourists in major cities like Dubai, Abu Dhabi, and Sharjah, contributing to the market's notable rise.
Numerous service providers are present on the market, providing a variety of choices, such as conventional bicycles and electric scooters, the latter of which are especially well-liked because of how simple it is to ride one around an urban area.
Even while the market is expanding and becoming more popular, there are still issues to be resolved, such as making sure that bikes are safe in traffic, addressing the need for improved infrastructure for cycling, and making sure that shared bikes and e-scooters are maintained properly.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @
Updated Version 2024 is available our Sample Report May Includes the:
Scope For 2024
Brief Introduction to the research report.
Table of Contents (Scope covered as a part of the study)
Top players in the market
Research framework (structure of the report)
Research methodology adopted by Worldwide Market Reports
Leading players involved in the UAE Bike Sharing Market include:
Careem Bikes (UAE), Byky Stations (UAE), Arnab (UAE), Lime (US), Bird (US), Circ (Germany), Mobike (China), Jump Bikes (US), Yulu (India), Nextbike (Germany), OBike (Singapore), Aventon Pace (US), VeoRide (US), Wheels (US), Hive (UAE), Beam (UAE), Hawk (UAE), S'COOL Bikes (UAE), ShareaBike (UAE), Yassir (UAE), and Other Major Players.
Moreover, the report includes significant chapters such as Patent Analysis, Regulatory Framework, Technology Roadmap, BCG Matrix, Heat Map Analysis, Price Trend Analysis, and Investment Analysis which help to understand the market direction and movement in the current and upcoming years.
If You Have Any Query UAE Bike Sharing Market Report, Visit:
Segmentation of UAE Bike Sharing Market:
By Bike Type
Traditional Bike
E-bike
By Sharing System
Docked
Dockless
By User Type
Tourists and Visitors
Regular Commuters
Highlights from the report:
Market Study: It includes key market segments, key manufacturers covered, product range offered in the years considered, Global UAE Bike Sharing Market, and research objectives. It also covers segmentation study provided in the report based on product type and application.
Market Executive Summary: This section highlights key studies, market growth rates, competitive landscape, market drivers, trends, and issues in addition to macro indicators.
Market Production by Region: The report provides data related to imports and exports, revenue, production and key players of all the studied regional markets are covered in this section.
UAE Bike Sharing Market Profiles of Top Key Competitors: Analysis of each profiled Roll Hardness Tester market player is detailed in this section. This segment also provides SWOT analysis of individual players, products, production, value, capacity, and other important factors.
If you require any specific information that is not covered currently within the scope of the report, we will provide the same as a part of the customization.
Acquire This Reports: -
About Us:
We are technocratic market research and consulting company that provides comprehensive and data-driven market insights. We hold the expertise in demand analysis and estimation of multidomain industries with encyclopedic competitive and landscape analysis. Also, our in-depth macro-economic analysis gives a bird's eye view of a market to our esteemed client. Our team at Pristine Intelligence focuses on result-oriented methodologies which are based on historic and present data to produce authentic foretelling about the industry. Pristine Intelligence's extensive studies help our clients to make righteous decisions that make a positive impact on their business. Our customer-oriented business model firmly follows satisfactory service through which our brand name is recognized in the market.
Contact Us:
Office No 101, Saudamini Commercial Complex,
Right Bhusari Colony,
Kothrud, Pune,
Maharashtra, India - 411038 (+1) 773 382 1049 +91 - 81800 - 96367
Email: [email protected]
#UAE Bike Sharing#UAE Bike Sharing Market#UAE Bike Sharing Market Size#UAE Bike Sharing Market Share#UAE Bike Sharing Market Growth#UAE Bike Sharing Market Trend#UAE Bike Sharing Market segment#UAE Bike Sharing Market Opportunity#UAE Bike Sharing Market Analysis 2023
0 notes
Text
UAE Bike Sharing Market: Forthcoming Trends and Share Analysis by 2030

The UAE Bike Sharing is Expected to Grow at a Significant Growth Rate, and the Forecast Period is 2023-2030, Considering the Base Year as 2022.
The industry in the United Arab Emirates that offers shared bicycles and electric scooters (also known as e-scooters) for short-term public rentals is known as the "UAE bike-sharing market." Through mobile apps or docking stations positioned thoughtfully around different urban locations, customers may rent bikes and e-scooters for short distances with ease thanks to this creative transportation idea. Bike-sharing programs have been a popular choice for both residents and tourists in major cities like Dubai, Abu Dhabi, and Sharjah, contributing to the market's notable rise.
Numerous service providers are present on the market, providing a variety of choices, such as conventional bicycles and electric scooters, the latter of which are especially well-liked because of how simple it is to ride one around an urban area.
Even while the market is expanding and becoming more popular, there are still issues to be resolved, such as making sure that bikes are safe in traffic, addressing the need for improved infrastructure for cycling, and making sure that shared bikes and e-scooters are maintained properly.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @
Updated Version 2024 is available our Sample Report May Includes the:
Scope For 2024
Brief Introduction to the research report.
Table of Contents (Scope covered as a part of the study)
Top players in the market
Research framework (structure of the report)
Research methodology adopted by Worldwide Market Reports
Leading players involved in the UAE Bike Sharing Market include:
Careem Bikes (UAE), Byky Stations (UAE), Arnab (UAE), Lime (US), Bird (US), Circ (Germany), Mobike (China), Jump Bikes (US), Yulu (India), Nextbike (Germany), OBike (Singapore), Aventon Pace (US), VeoRide (US), Wheels (US), Hive (UAE), Beam (UAE), Hawk (UAE), S'COOL Bikes (UAE), ShareaBike (UAE), Yassir (UAE), and Other Major Players.
Moreover, the report includes significant chapters such as Patent Analysis, Regulatory Framework, Technology Roadmap, BCG Matrix, Heat Map Analysis, Price Trend Analysis, and Investment Analysis which help to understand the market direction and movement in the current and upcoming years.
If You Have Any Query UAE Bike Sharing Market Report, Visit:
Segmentation of UAE Bike Sharing Market:
By Bike Type
Traditional Bike
E-bike
By Sharing System
Docked
Dockless
By User Type
Tourists and Visitors
Regular Commuters
Highlights from the report:
Market Study: It includes key market segments, key manufacturers covered, product range offered in the years considered, Global UAE Bike Sharing Market, and research objectives. It also covers segmentation study provided in the report based on product type and application.
Market Executive Summary: This section highlights key studies, market growth rates, competitive landscape, market drivers, trends, and issues in addition to macro indicators.
Market Production by Region: The report provides data related to imports and exports, revenue, production and key players of all the studied regional markets are covered in this section.
UAE Bike Sharing Market Profiles of Top Key Competitors: Analysis of each profiled Roll Hardness Tester market player is detailed in this section. This segment also provides SWOT analysis of individual players, products, production, value, capacity, and other important factors.
If you require any specific information that is not covered currently within the scope of the report, we will provide the same as a part of the customization.
Acquire This Reports: -
About Us:
We are technocratic market research and consulting company that provides comprehensive and data-driven market insights. We hold the expertise in demand analysis and estimation of multidomain industries with encyclopedic competitive and landscape analysis. Also, our in-depth macro-economic analysis gives a bird's eye view of a market to our esteemed client. Our team at Pristine Intelligence focuses on result-oriented methodologies which are based on historic and present data to produce authentic foretelling about the industry. Pristine Intelligence's extensive studies help our clients to make righteous decisions that make a positive impact on their business. Our customer-oriented business model firmly follows satisfactory service through which our brand name is recognized in the market.
Contact Us:
Office No 101, Saudamini Commercial Complex,
Right Bhusari Colony,
Kothrud, Pune,
Maharashtra, India - 411038 (+1) 773 382 1049 +91 - 81800 - 96367
Email: [email protected]
#UAE Bike Sharing#UAE Bike Sharing Market#UAE Bike Sharing Market Size#UAE Bike Sharing Market Share#UAE Bike Sharing Market Growth#UAE Bike Sharing Market Trend#UAE Bike Sharing Market segment#UAE Bike Sharing Market Opportunity#UAE Bike Sharing Market Analysis 2023
0 notes
Text
Hive Hadoop

Hive and Hadoop are essential components in big data and data analytics. Here’s an overview:
Hadoop: Hadoop is an open-source framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale from single servers to thousands of machines, each offering local computation and storage. The key components of Hadoop include:
Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Hive: Hive is a data warehouse software project built on top of Hadoop to provide data querying and analysis. Hive gives an SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop, including the HDFS, Apache HBase, and Amazon S3 filesystems. It is used for:
Data summarization, query, and analysis: Hive provides tools for easy data summarization, ad-hoc query, and analysis of large datasets stored in Hadoop-compatible file systems.
HiveQL: Hive defines a simple SQL-like query language, HiveQL, which can be used to query, summarize, explore, and analyze data. Under the hood, HiveQL queries are converted into a series of MapReduce, Tez, or Spark jobs for execution on Hadoop.
Both Hive and Hadoop are essential for handling big data, especially for large-scale data processing and analysis tasks. They are widely used in industries that handle large volumes of data, such as e-commerce, finance, telecommunications, and more. Their scalability and efficiency make them ideal for businesses leveraging data for strategic decision-making.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Text
Buzz-Free Living: Navigating the Hive of Honey Bee Removal Services Near Me
The delicate balance between coexistence and safety often comes to the forefront when honey bees decide to establish their hives near human dwellings. As these crucial pollinators play a vital role in our ecosystem, it's essential to address the issue with care and responsibility. In this article, you will explore the key factors surrounding honey bee removal services, providing insights into the importance of their role, the risks involved, and how to find the suitable "Honey Bee Removal Service near me."
Understanding the Importance of Honey Bees: Nature's Pollinators
Ecosystem Harmony
Before delving into the need for a honey bee removal service near me, it's crucial to acknowledge the pivotal role honey bees play in maintaining ecological balance. These industrious insects are essential pollinators, facilitating the reproduction of flowering plants, fruits, and vegetables. Without them, our agricultural landscape and natural ecosystems would suffer, impacting food production and biodiversity.
Urban Dilemma: The Need for Coexistence
While honey bees are undoubtedly beneficial, their proximity to human habitation can pose risks. Hives established in or around homes, schools, or public spaces may lead to unwanted encounters, triggering safety concerns. Allergic reactions to bee stings, especially in populated areas, highlight the necessity of managing honey bee colonies responsibly.
Choosing the Right Honey Bee Removal Service: Key Factors to Consider
Professional Expertise: Experience Matters
When searching for a "Honey Bee Removal Service near me," prioritize professionals with extensive experience in bee removal. A knowledgeable team is equipped to assess the situation, devise a safe removal plan, and execute it efficiently. Look for services that adhere to ethical bee removal practices, emphasizing relocation rather than extermination.
Safety Protocols: Protecting People and Bees
Safety is paramount during honey bee removal. Reputable services prioritize the safety of both their team and the residents. This includes using protective gear, implementing secure removal techniques, and ensuring that bystanders are kept at a safe distance during the process. Ask about their safety protocols before committing to a service.
Environmentally Friendly Practices: Bee-Friendly Solutions
The best honey bee removal services understand the ecological importance of bees and adopt practices that prioritize their preservation. Look for services that specialize in live bee removal and relocation. This eco-friendly approach ensures that the bees are transported to a suitable habitat rather than exterminated.
Transparent Communication: Clear Plans and Pricing
Choose a removal service that communicates transparently about its process, potential challenges, and pricing. A reputable service provides a clear plan of action, detailing the steps involved in the removal process. Transparent pricing ensures that you are aware of the costs upfront, preventing any surprises after the service is rendered.
"Honey Bee Removal Service near me" is not just a search query; it's a call to balance the need for coexistence with the imperative of safety. As conscientious stewards of the environment, we must recognize the importance of honey bees while addressing the potential risks they pose in close quarters.
0 notes
Text
What is Amazon EMR? How to create Amazon EMR clusters

Describe Amazon EMR.
Amazon EMR, previously Amazon Elastic MapReduce, allows Apache Hadoop and Apache Spark easy to run on AWS for processing and analysing enormous amounts of data. These frameworks and open-source apps process data for corporate intelligence and analytics. Amazon EMR transforms and transfers massive volumes of data between Amazon DynamoDB and Amazon S3..
Amazon EMR cluster setup and operation
A detailed overview of Amazon EMR clusters, including how to submit work, how data is handled, and the cluster's processing phases.
Learning nodes and clusters
Main component of Amazon EMR is cluster. Amazon EC2 clusters are groups of instances. Every cluster instance is a node. Each cluster node type has a role. Amazon EMR puts software components on each node type to assign it a function in a distributed application like Apache Hadoop.
Types of Amazon EMR nodes:
The primary node runs software to coordinate work and data allocation across processing nodes, administering the cluster. The primary node monitors cluster health and tasks. Every cluster has a primary node that can form a single-node cluster.
The core node contains the software needed to run operations and store data in your cluster's Hadoop Distributed File System. Core nodes are present in multi-node clusters.
Task nodes: Software-equipped nodes that execute tasks without storing data in HDFS. Task nodes are optional.
Submitted work to cluster
When running an Amazon EMR cluster, you may specify tasks in several ways.
Provide clear instructions for cluster construction phases. This is frequently done to clusters that process a particular amount of data and then shut down.
Submit steps, including jobs, using the Amazon EMR UI, API, or CLI after constructing a long-running cluster. Check out Submit work to an Amazon EMR cluster.
Establish a cluster, connect to the primary node and other nodes via SSH, then complete tasks and send interactive or scripted queries using the installed apps' interfaces. Learn more from the Amazon EMR Release Guide.
Data processing
When you launch your cluster, you choose data processing frameworks and apps. You can process data in your Amazon EMR cluster by performing steps in the cluster or sending jobs or queries to installed apps.
Jobs posted directly to applications
Your Amazon EMR cluster's software lets you submit jobs and communicate with it. This is usually done by connecting securely to the primary node and utilising the tools and interfaces for your cluster's software.
Executing data processing procedures
Amazon EMR clusters can receive ordered steps. Each stage contains data modification instructions for the cluster's software.
The following procedure has four steps:
Submit a dataset for processing.
Process first-stage output with Pig.
Hive can process a second input dataset.
Make an output dataset.
Amazon EMR usually processes data from your chosen file system, such as HDFS or Amazon S3. This data progresses via processing. The output data is written to an Amazon S3 bucket in the last stage.
Steps are performed in this order:
Start processing is requested.
All actions are pending.
It becomes RUNNING when the sequence starts. The remaining steps are PENDING.
After the first stage, it becomes COMPLETED.
Once the sequence continues, its status becomes RUNNING. Its condition is COMPLETED when done.
This cycle continues until all stages are completed and processing is complete.
The following diagram shows processing steps and state changes.
Failure while processing marks a step as FAILED. Choose a follow-up for each stage. If a previous step fails, the remaining steps are set to CANCELLED and do not execute. Other alternatives include stopping the cluster immediately or disregarding the failure and continuing.
The figure shows the default state change and step sequence when a processing step fails.
Understanding cluster lifespan
Successful Amazon EMR clusters work like this:
Amazon EMR creates EC2 instances in the cluster for each instance based on your requirements. See Amazon EMR cluster hardware and networking configuration for more. Amazon EMR always utilises the default AMI or your custom Amazon Linux AMI. For more, see Using a custom AMI to increase Amazon EMR cluster configuration flexibility. The cluster state is just beginning.
You can configure bootstrap activities for each Amazon EMR instance. Custom apps can be installed and customised using bootstrap activities. Read Create bootstrap actions for Amazon EMR cluster software installation. Currently, the cluster is BOOTSTRAPPING.
Amazon EMR may install native apps like Hive, Hadoop, Spark, and others when you establish the cluster. After startup and native application installation, the cluster is RUNNING. After connecting to cluster instances, the cluster will execute the sequential steps you selected when you established it. Submit further actions after prior steps are complete. Check out Submit work to an Amazon EMR cluster.
A successful step puts the cluster in WAITING.
Following the last phase, an auto-terminating cluster enters TERMINATING before terminating. Waiting requires manually shutting down the cluster. After a manual shutdown, the cluster enters TERMINATING before TERMINATED.
Amazon EMR terminates the cluster and all instances if a cluster lifecycle failure occurs without termination protection. If a cluster fails, its data is destroyed and its status changed to TERMINATED_WITH_ERRORS. If configured, you can restore data, deactivate termination protection, and end the cluster. Find out how termination protection can prevent unintended shutdown of Amazon EMR clusters.
This image shows the cluster lifespan and how each stage corresponds to a cluster state.
#AmazonEMR#AmazonEMRclusters#AmazonEC2#AmazonEMRAPI#AmazonS3#AmazonS3bucket#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
HiveQL Execution Flow: From Query to Result
HiveQL Execution Flow Explained: How Queries Are Processed from Start to Finish Hello, Hive enthusiasts! In this blog post, I will introduce you to one of the most crucial concepts in Hive: HiveQL Execution Flow. Understanding how Hive processes queries is essential for optimizing performance and managing large datasets efficiently. HiveQL follows a structured execution process, from parsing and…
0 notes
Text
Exploiting Apache Spark's Potential: Changing Enormous Information InvestigationPresentation
In the realm of huge information examination, Apache Flash has arisen as a distinct advantage. Spark is now the preferred framework for handling large-scale data processing tasks due to its lightning-fast processing and advanced analytics capabilities. In this blog, we'll talk about how Apache Spark has changed big data analytics and the amazing features and benefits it offers.
The Ecosystem of Spark:
Apache Flash is an open-source, dispersed figuring framework that gives a broad environment to enormous information handling. It provides a single platform for a variety of data processing tasks, including machine learning, graph processing, batch processing, and real-time streaming. Flash's adaptable design permits it to flawlessly coordinate with well known huge information innovations like Hadoop, Hive, and HBase, making it a flexible device for information specialists and information researchers.
Lightning-Quick Handling:
Spark's exceptional processing speed is one of the main reasons for its popularity. Flash use in-memory registering, empowering it to store information in Smash and perform calculations in-memory. When compared to conventional disk-based systems, this significantly reduces the disk I/O overhead, resulting in significantly quicker processing times. Flash's capacity to convey information and calculations across a group of machines likewise adds to its superior presentation abilities.
Distributed resilient datasets (RDDs):
RDDs are the principal information structure in Apache Flash. They are shortcoming open minded, unchanging assortments of items that can be handled in lined up across a bunch. Because they automatically handle data partitioning and fault tolerance, RDDs enable effective distributed processing. Complex data manipulations and aggregations are made possible by RDDs' support for a variety of transformations and actions.
DataFrames and Spark SQL:
A higher-level interface for working with structured and semi-structured data is provided by Spark SQL. It seamlessly integrates with Spark's RDDs and lets users query data using SQL syntax. DataFrames, which are a more effective and optimized approach to working with structured data, are also included in Spark SQL. DataFrames provide a user-friendly tabular structure and enable data manipulations that take full advantage of Spark's distributed processing capabilities.
AI with MLlib:
Flash's MLlib library works on the execution of adaptable AI calculations. MLlib gives a rich arrangement of AI calculations and utilities that can be consistently incorporated with Flash work processes. Its conveyed nature considers preparing models on enormous datasets, making it reasonable for dealing with huge information AI assignments. In addition, hyperparameter tuning, pipeline construction, and model persistence are all supported by MLlib.
Processing Streams Using Spark Streaming:
Flash Streaming empowers continuous information handling and investigation. It ingests information in little, miniature group spans, considering close to constant handling. Spark Streaming is able to deal with enormous streams of data and carry out intricate calculations in real time thanks to its integration with well-known messaging systems like Apache Kafka. This makes it ideal for applications like extortion location, log examination, and IoT information handling.
Capabilities for Spark's Graph Processing:
Flash's GraphX library gives a versatile system to chart handling and investigation. It permits clients to control and investigate huge scope chart information productively. GraphX is a useful tool for
applications like social network analysis, recommendation systems, and network topology analysis because it supports a wide range of graph algorithms.
Conclusion:
By providing a powerful, adaptable, and effective framework for processing and analyzing massive datasets, Apache Spark has revolutionized big data analytics. It is the preferred choice for both data engineers and data scientists due to its lightning-fast processing capabilities, extensive ecosystem, and support for various data processing tasks. Spark is poised to play a crucial role in the future of big data analytics by driving innovation and uncovering insights from massive datasets with continued development and adoption.
Find more information @ https://olete.in/?subid=165&subcat=Apache Spark
0 notes
Text
Post 35 | HDPCD | Insert records from NON-ORC table into ORC table
Insert records from NON-ORC table into ORC table
Hello, everyone. Thanks for going through the tutorials. The increasing views and visitors act as a motivation for me.
In the last tutorial, we saw how to define a hive ORC table. In this tutorial, we are going to load data in that ORC table from an NON-ORC table.
For doing this, we are going to follow the below process.

Loading records into ORC table from NON-ORC table
As you can see from the…
View On WordPress
#apache#apache hive#apache hive internal and external table#Big Data#big data certification#big data tutorial#bucketed table in hive#create external table in hive#create hive bucketed table#create hive table#create table in apache hive#create table in hive#created hive bucketed table#csv to hive#data#Data Sources#datatype#define a bucketed hive table#defining a bucketed hive table#execute hive query#external table in hive#hadoop hive#HDPCD#hdpcd big data#hdpcd certification#Hive#hive 1.1.1#hive and hcatalog#hive and pig#hive bucketed table
0 notes
Text
Silvan and Madrid
Two Guardians sat on a boulder on a cliff overlooking the Dreaming City. Lakes and rivers of mist billowed between the jagged mountain ranges, obscuring the buildings. Trees appeared and disappeared, their wind-twisted forms graceful and strange. The wind caught the tattered cloak of one of the Guardians, making it flap like a flag.
"How long has it been?" asked the warlock, her voice soft. She wore Braytech researcher robes over a thermal undersuit. The harsh V-shaped neck and yoke accented her figure.
"Thirty-four cycles," said the hunter wearily. He rested his elbows on his knees, shoulders slumped. His gauntlets were cracked and held together with layers of resin. "Three weeks a cycle. Two years and change."
The warlock rested a hand on his shoulder. "Don't give up, Madrid. Your sentence can't last forever."
"There's no reason why it should ever end," Madrid said. His glowing eyes were the amber of a light preparing to burn out. "I can't make up to the Queen for killing her brother. She'll punish me for the rest of my life." He held up one hand, displaying his torn glove. "My gear is falling apart. I've fought the same enemies every day for two years. There's no winning. The Corsairs have it worse off than I do. I can visit Reefedge, but they can't leave at all."
"They volunteered," said the warlock. Her skin was a lighter shade of blue than his. Her hair was bright red, and glowing freckles sprinkled her cheeks like stars. "They receive regular care packages from elsewhere in the Reef. But not you. It's not fair."
"I'm a prisoner, Silvan," Madrid said. "I don't deserve anything."
They watched the sun sink below the mists, turning them gold and pink. The many moons of the asteroid field overhead grew brighter.
"Well," said Silvan, "I'm going to have a word with the Queen about you."
"Don't bother," Madrid said. "She's left her court. Nobody knows where she is."
"You underestimate me," Silvan said. Her silver eyes flashed. "I'm a Gensym Scribe. My job is finding out things. Usually it's things that stubborn planets and moons would rather keep to themselves and kill me along the way. But if I can figure out how to enter the mines of Saturn, I can find Mara Sov."
Madrid raised an eyebrow. "Saturn has mines? What do they dig out, gas?"
"Yes," Silvan replied. "And very interesting types of ice. My point is, don't lose heart. We're very anxious about Earth's moon. Eris Morn's been there for weeks without responding to our queries. I'm on the hook for going to investigate, and I want you on my fireteam."
"It'll never happen," Madrid said, his voice low and exhausted. "Get Jayesh Khatri to help you."
Silvan suddenly beamed. "Oh, I'd love to run missions with Jayesh Khatri. But he's busy with his own fireteam. Plus … he's married."
Madrid blinked at her.
"Oh, nevermind," Silvan said, blushing. "He just published the most amazing book, all about how to use the Light in precise ways, and he signed my copy, and … anyway."
Madrid looked disgusted and stared at the horizon.
"Don't be like that," Silvan said. "I'm over him, I swear."
"I was on his first fireteam," Madrid said, very quietly.
Silvan was quiet a moment. Then she said, "I know."
"You know why we're not, anymore?"
Silvan stared at the ground. "I never asked. Don't tell me, Madrid. I don't want to … think less of either of you." She fixed her silver eyes on his face. "You were always my friend from the time I arrived at the Tower. You're the one who got me interested in studying Jupiter's moons. And now … Madrid, you're dying. Your Light is weaker every time I visit. You've got to get out of here. And Traveler help me, I will make Mara Sov see reason."
"And what if you make my sentence worse?" Madrid growled. "She could have my Ghost executed and throw me to the Nine. She gave them Skolas. He came back insane."
"Then I'm going to kidnap you," Silvan said. She tapped the prisoner's bracelet locked around his arm. "My Ghost is a hacker. He'll have this off you in a day. Then Sov will never find you."
Madrid grinned, in spite of himself. "Thought this through, have you?"
"Desperate times call for desperate measures," Silvan said, smiling. "I am not setting foot on the moon by myself. The Hive have been building this crazy fortress there. Dad told me that I need to make my own fireteam instead of relying on him and Yuna all the time. You were my first pick."
"Know any Titans?" Madrid asked. "We need one for a complete team."
"I'm working on it," said Silvan with such confidence that Madrid was sure she didn't know a single one. Her father, Ivaran, was a Titan, and had always been the head of their family fireteam. Silvan hadn't interacted much with the warriors beyond that.
Madrid held up a hand and summoned his Ghost. Rose appeared in a swirl of transmat particles. She wore a handmade shell in the shape of a rosebud. Her blue eye blinked at him fondly. While shy of appearing around strangers, Rose didn't mind Silvan.
"What do you think?" he asked her. "Should Silvan try it?"
"There's no harm in speaking to the Queen," Rose said softly. "This time loop is slowly killing us both. Besides, Mara Sov might be merciful. Silvan might catch her on a good day."
Madrid gazed into his Ghost's eye for a long moment. She was integrated so deeply into his mind that he was able to send her a thought question and receive a reply at the speed of light.
Uldren?
No.
The Awoken Prince had been revived as a Guardian, but nobody knew what had become of him. Madrid kept hoping that Uldren would show up and meet the Queen--maybe punch her lights out--and Madrid would be freed. But then, it was well known how much Mara Sov hated Guardians. She might punish Madrid worse for allowing her brother to come back as one.
But he didn't tell Silvan this. Uldren's resurrection was a secret that Madrid and Jayesh had kept for a year and a half.
Silvan climbed to her feet. "It's settled. I'm going to speak to Mara Sov. If you don't hear from me in a few days, assume she blasted me to atoms."
"Don't say that," Madrid began. Then he met Silvan's eyes and saw no trace of a joke there. She gazed at him for a second, then looked away. Silvan was afraid.
He touched her shoulder. "You don't have to do this."
"I have to try," she murmured. Her voice strengthened as she squared her shoulders. "Somebody has to stand up for you, Madrid. It's high time your sentence was lifted."
He escorted her down the hill to where her ship waited in the mist. As she prepared to transmat inside, Madrid said, "Thank you."
"Don't thank me, yet," Silvan said without looking at him. "I don't even know if I can find the Queen."
"You found the Mines of Saturn," Madrid pointed out.
Silvan drew a deep breath, then exhaled. "The Mines weren't actively avoiding Guardians." She transmatted away, leaving Madrid alone, and worried.
6 notes
·
View notes
Text
UAE Bike Sharing Market: Forthcoming Trends and Share Analysis by 2030

The UAE Bike Sharing is Expected to Grow at a Significant Growth Rate, and the Forecast Period is 2023-2030, Considering the Base Year as 2022.
The industry in the United Arab Emirates that offers shared bicycles and electric scooters (also known as e-scooters) for short-term public rentals is known as the "UAE bike-sharing market." Through mobile apps or docking stations positioned thoughtfully around different urban locations, customers may rent bikes and e-scooters for short distances with ease thanks to this creative transportation idea. Bike-sharing programs have been a popular choice for both residents and tourists in major cities like Dubai, Abu Dhabi, and Sharjah, contributing to the market's notable rise.
Numerous service providers are present on the market, providing a variety of choices, such as conventional bicycles and electric scooters, the latter of which are especially well-liked because of how simple it is to ride one around an urban area.
Even while the market is expanding and becoming more popular, there are still issues to be resolved, such as making sure that bikes are safe in traffic, addressing the need for improved infrastructure for cycling, and making sure that shared bikes and e-scooters are maintained properly.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @
Updated Version 2024 is available our Sample Report May Includes the:
Scope For 2024
Brief Introduction to the research report.
Table of Contents (Scope covered as a part of the study)
Top players in the market
Research framework (structure of the report)
Research methodology adopted by Worldwide Market Reports
Leading players involved in the UAE Bike Sharing Market include:
Careem Bikes (UAE), Byky Stations (UAE), Arnab (UAE), Lime (US), Bird (US), Circ (Germany), Mobike (China), Jump Bikes (US), Yulu (India), Nextbike (Germany), OBike (Singapore), Aventon Pace (US), VeoRide (US), Wheels (US), Hive (UAE), Beam (UAE), Hawk (UAE), S'COOL Bikes (UAE), ShareaBike (UAE), Yassir (UAE), and Other Major Players.
Moreover, the report includes significant chapters such as Patent Analysis, Regulatory Framework, Technology Roadmap, BCG Matrix, Heat Map Analysis, Price Trend Analysis, and Investment Analysis which help to understand the market direction and movement in the current and upcoming years.
If You Have Any Query UAE Bike Sharing Market Report, Visit:
Segmentation of UAE Bike Sharing Market:
By Bike Type
Traditional Bike
E-bike
By Sharing System
Docked
Dockless
By User Type
Tourists and Visitors
Regular Commuters
Highlights from the report:
Market Study: It includes key market segments, key manufacturers covered, product range offered in the years considered, Global UAE Bike Sharing Market, and research objectives. It also covers segmentation study provided in the report based on product type and application.
Market Executive Summary: This section highlights key studies, market growth rates, competitive landscape, market drivers, trends, and issues in addition to macro indicators.
Market Production by Region: The report provides data related to imports and exports, revenue, production and key players of all the studied regional markets are covered in this section.
UAE Bike Sharing Market Profiles of Top Key Competitors: Analysis of each profiled Roll Hardness Tester market player is detailed in this section. This segment also provides SWOT analysis of individual players, products, production, value, capacity, and other important factors.
If you require any specific information that is not covered currently within the scope of the report, we will provide the same as a part of the customization.
Acquire This Reports: -
About Us:
We are technocratic market research and consulting company that provides comprehensive and data-driven market insights. We hold the expertise in demand analysis and estimation of multidomain industries with encyclopedic competitive and landscape analysis. Also, our in-depth macro-economic analysis gives a bird's eye view of a market to our esteemed client. Our team at Pristine Intelligence focuses on result-oriented methodologies which are based on historic and present data to produce authentic foretelling about the industry. Pristine Intelligence's extensive studies help our clients to make righteous decisions that make a positive impact on their business. Our customer-oriented business model firmly follows satisfactory service through which our brand name is recognized in the market.
Contact Us:
Office No 101, Saudamini Commercial Complex,
Right Bhusari Colony,
Kothrud, Pune,
Maharashtra, India - 411038 (+1) 773 382 1049 +91 - 81800 - 96367
Email: [email protected]
#UAE Bike Sharing#UAE Bike Sharing Market#UAE Bike Sharing Market Size#UAE Bike Sharing Market Share#UAE Bike Sharing Market Growth#UAE Bike Sharing Market Trend#UAE Bike Sharing Market segment#UAE Bike Sharing Market Opportunity#UAE Bike Sharing Market Analysis 2023
0 notes